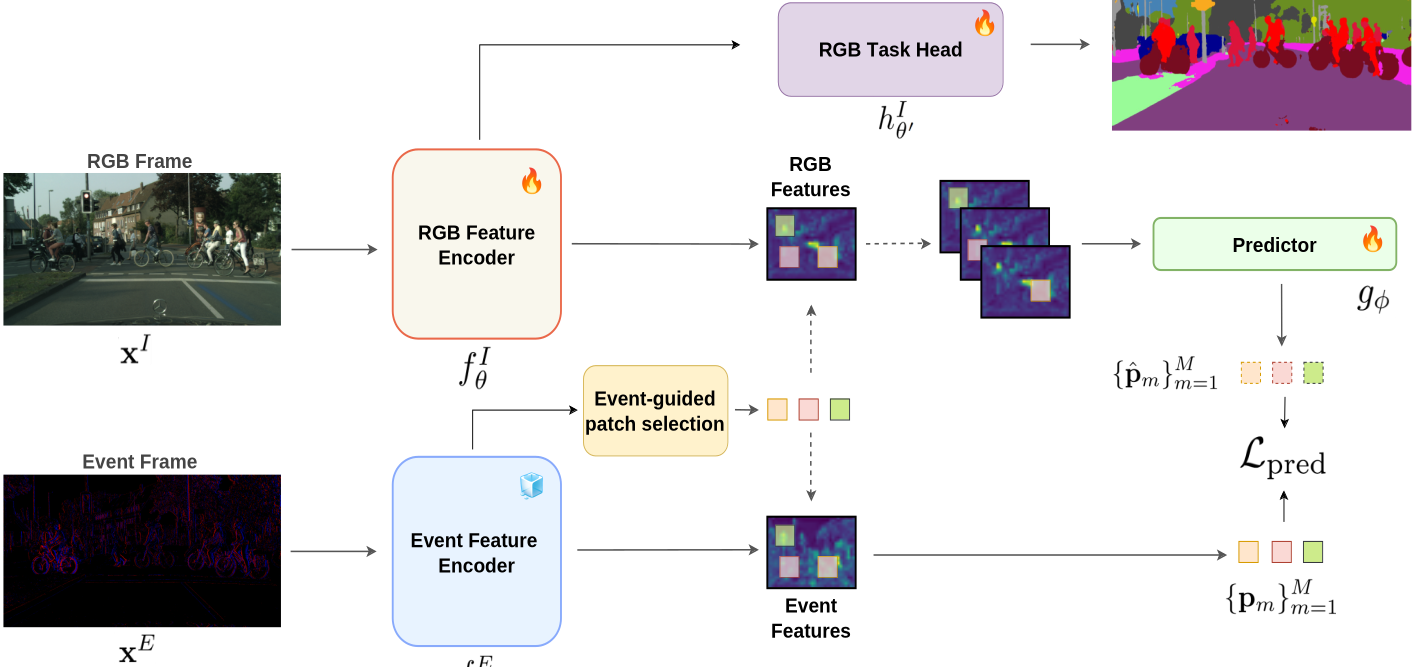
Deep neural networks for visual perception are highly susceptible to domain shift,
limiting their deployment under conditions that differ from the training data.
We address this problem through a cross-modal Learning Using Privileged Information
framework, where event cameras are available only during training and the final model
remains RGB-only at inference.
RGB streams are semantically dense but domain-dependent, while event streams are sparse
yet more domain-invariant. Direct feature alignment between these modalities is therefore
suboptimal, as it can force RGB representations to mimic sparse event features and lose
semantic detail. To overcome this, we introduce
Privileged Event-based Predictive Regularization:
RGB features are trained to predict event-derived latent representations in a shared
feature space, transferring event robustness without direct alignment or input reconstruction.
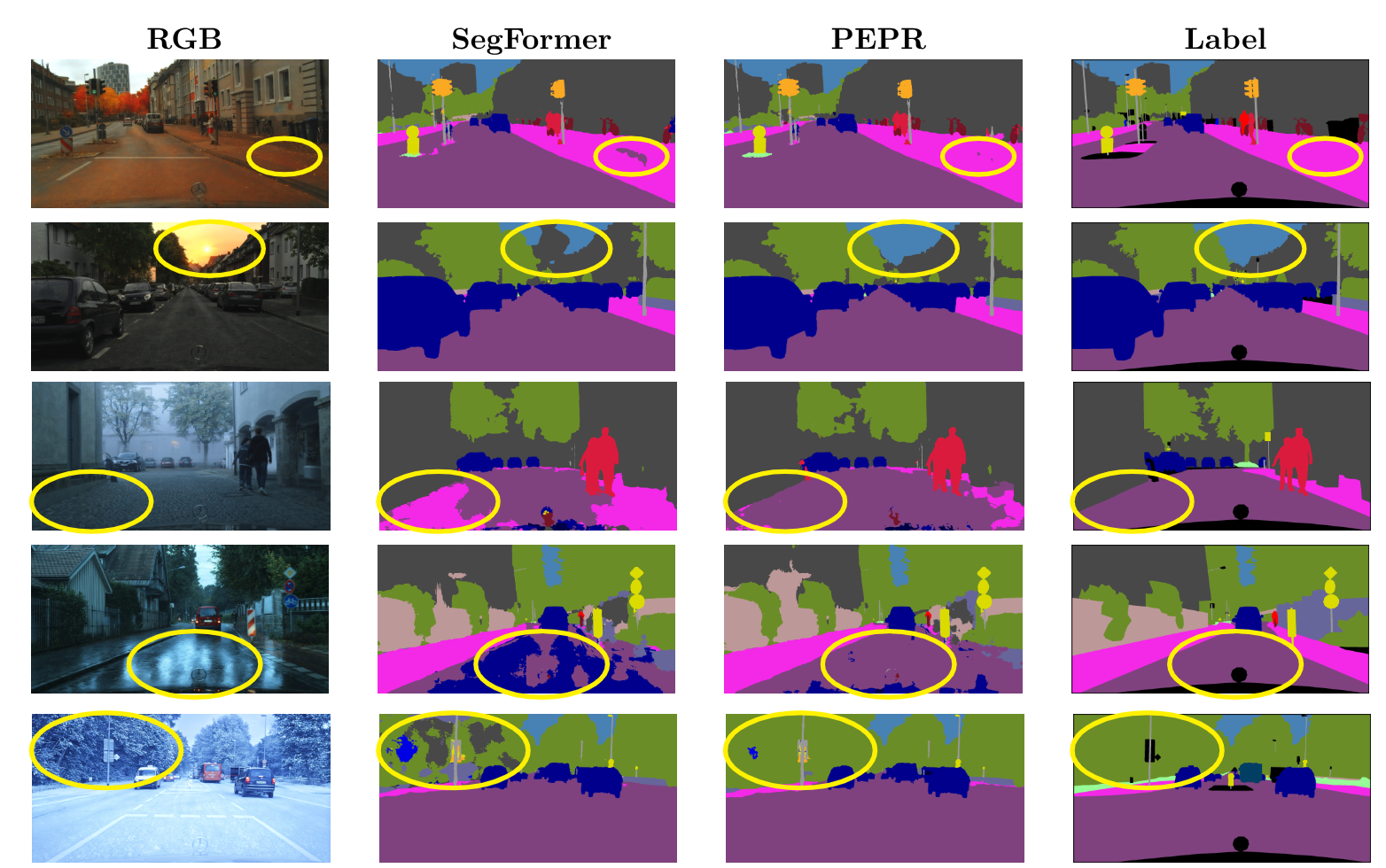
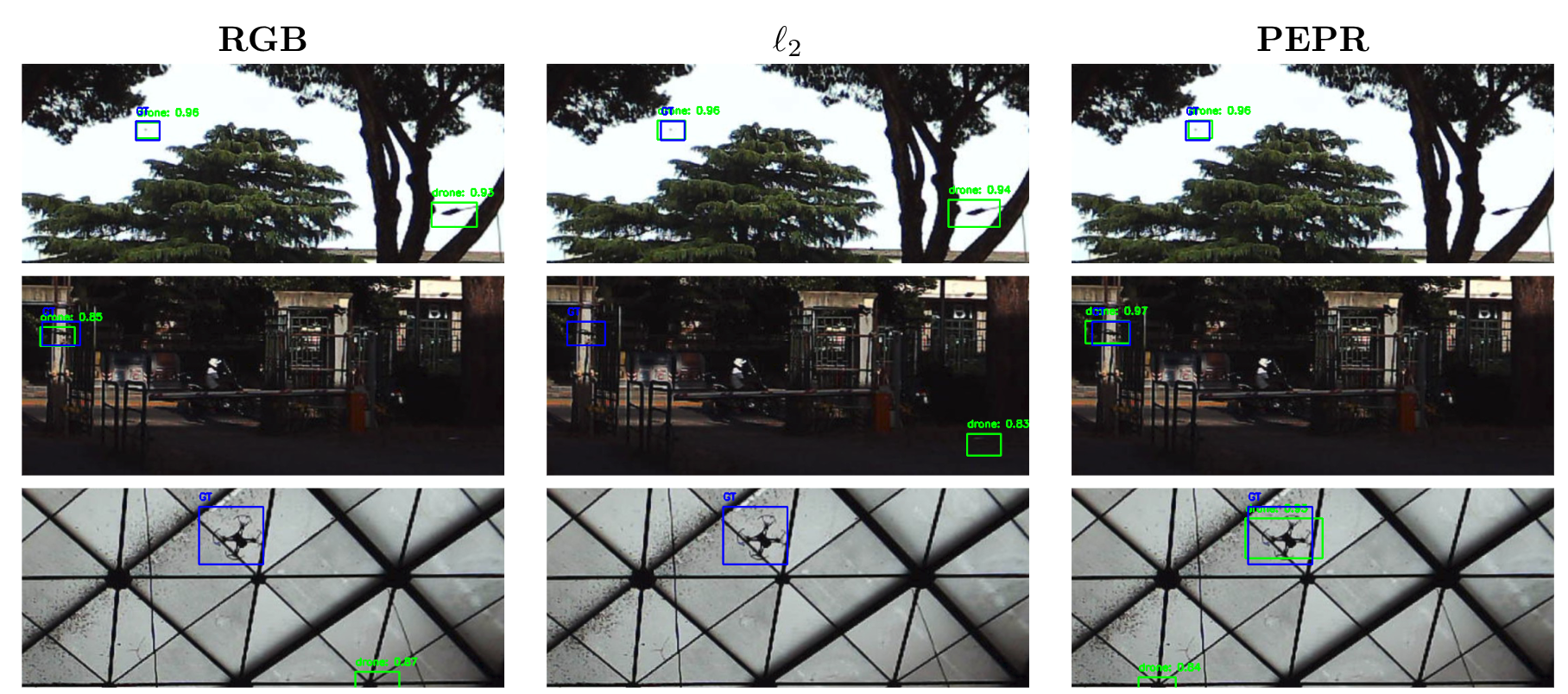
PEPR improves robustness to day-to-night and adverse domain shifts across object detection
and semantic segmentation, while preserving a standard RGB-only inference pipeline.